For this problem, we are provided with a USB PCAP. These types of challenges typically will hide the flag in a way that’s associated with the purpose of the USB device (ie. typing out the flag for a keyboard or drawing out the flag for a mouse). The first thing to do is to figure out what type of USB device we’re dealing with. This will give us a better idea on what the data containing the flag may look like.
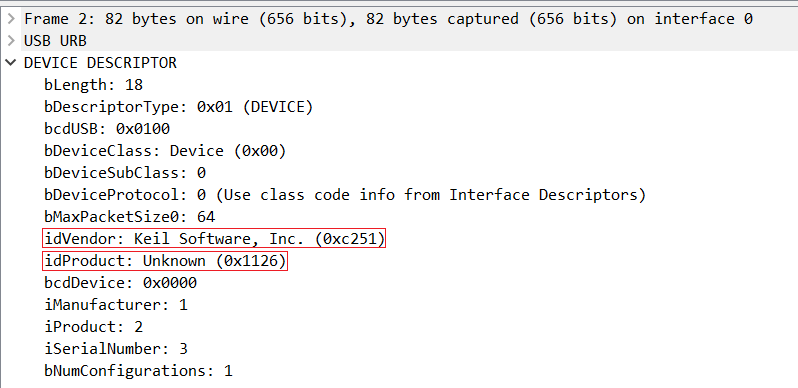
The GET DESCRIPTOR Response Device packet contains information on the USB device. The idVendor field identifies the vendor of the product and is a value assigned by the USB Organization. The idProduct specifies the product created by the vendor, and can tell us exactly which device we’re dealing with.
 Information on identifying the USB device.
Information on identifying the USB device.
The vendor for the USB device used in this PCAP was Keil Software, Inc. Looking up the product proved to be harder, but I eventually found the vendor and product id in an information file on Github. This identified the device as a EuroBraille Esys version 3.0+ with no SD card. Considering the information file was on a Google GitHub repo and a braille USB device would match the challenge name of “Feel It”, I assumed that this was the correct type of device. :^)
I did a little bit of research on the EuroBraille device to figure out what would be a reasonable method of encoding the flag. The EuroBraille device (such as the one below) is a refreshable braille display that encodes text as 8-dot braille.
 Example of a EuroBraille Esys device.
Example of a EuroBraille Esys device.
The repo this information came from, Google/brailleback, is an accessibility service that allows these types of displays to be hooked up to Android devices.
Once I knew that I was dealing with a USB braille reader, the next step was to figure out how data is sent by these types of devices.
I first checked the Leftover Capture Data from URB_INTERRUPT packets, as I had previously seen USB keyboard challenges that would send keystroke data in them. I wrote script to pull the leftover capture data from the device (1.9.2) to the host. However, this data did not change between packets except for the first byte, which increased by 1 each time.
On the BrailleBack repo, I found that there were some files for a EuroBraille driver. The writePacket function in eu_esysiris.c would write out STX at the beginning of each “packet” and ETX at the end of each “packet”. These were defined elsewhere as the bytes 0x02 and 0x03, respectively.
I simultaneously revisited the PCAP to look for places in packets that data could be stored. Another likely candidate was the SET_REPORT Request packets, as they contained data fragments that changed each time.
Some of the SET_REPORT Request packets started with STX or had an ETX near the end followed by a series of 0x55 bytes. The 0x55 bytes were padding at the end of the EuroBraille device packets. I noticed that if a SET_REPORT Request packet starting with STX was missing ETX at the end, the following SET_REPORT Request packet had more data and the ETX at the end. So it seems like EuroBraille Esys could split its information over more than one SET_REPORT Request packet if necessary. Below are two examples of EuroBraille Esys device packets in one or spread out over multiple SET_REPORT Request packets.
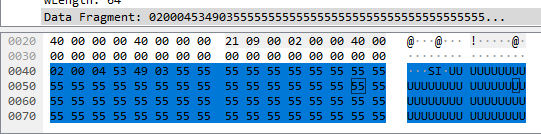 Example of a single Eurobraille Esys device packet.
Example of a single Eurobraille Esys device packet.
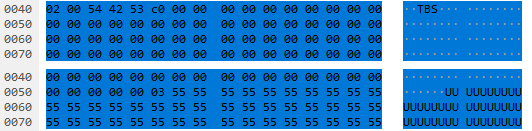 Example of a EuroBraille Esys device packet spread over multiple packets.
Example of a EuroBraille Esys device packet spread over multiple packets.
Now that I had an idea on where the data was stored, I needed to figure out how the braille keys were encoded.
The construction of the braille dot definitions seemed to reference some standard ISO-11548-1. Definitions elsewhere in the BrailleBack code showed that according to the ISO-11548-1 standard, a braille character was a single byte where each dot i was represented as the ith bit starting from the least significant bit.
I wrote up a quick script to pull out the data fragments from the SET_REPORT Request packets to work with. Out of convenience, I ended up attempting to convert each byte in the data fragment from braille to ASCII, although I definitely could have pulled out only the chunk between STX and ETX. There were also other bytes mixed in that related to BrailleBack’s packet structure, but I opted to ignore those for the time being.
I found bconv, a handy tool to convert braille to different formats. It could convert from dots to ASCII for me, so all I had to write was a conversion from byte to dots. Once I had the decoder set up to run on all the data fragments, I could read the output and ignore any non-ASCII characters to read the results. You can see some of the output below.
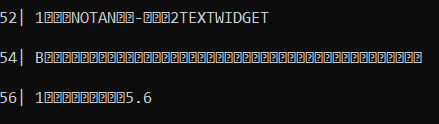
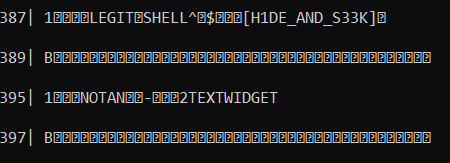
I found the text LEGIT SHELL $ [H1DE_AND_SEEK], which I took to be the flag. I assumed the square brackets were curly brackets, but still had a bit of trouble entering the flag since it seems that the letters were supposed to be lowercase. With a reminder from a teammate to try lowercase, I got the correct flag. :)
🚩 CTF{h1de_and_s33k} 🚩
My solve script is below and can also be downloaded here. The bconv repo was used in the solve script.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
#!/usr/bin/env python
from scapy.all import *
import subprocess
p = rdpcap("feel-it.pcap")
def main():
set_report_request()
def set_report_request():
global p
for i in range(len(p)):
data_fragments = ""
pkt = p[i]
if not pkt.haslayer(Raw):
continue
rawstr = str(pkt.getlayer(Raw))
# Check host -> 1.9.0 SET_REPORT Request
if rawstr[8] != '\x53' or rawstr[10] != '\x00' or rawstr[40] != '\x21':
continue
# Decode bytes in data fragment from bytes to dots
for b in rawstr[64:len(rawstr)]:
decode = byte_decode(ord(b))
if decode != "":
data_fragments += "p" + decode
# Output dots to ASCII conversion thanks to bconv
print str(i+1) + "| " + subprocess.check_output(['./bconv/bconv', '-f', 'd', '-t', 'a', data_fragments])
# Decodes a byte to dots
def byte_decode(b):
dots = ""
for i in range(8):
if ((b >> i) & 0x1) == 1:
dots += str(i+1)
dots.strip()
return dots
# Encodes a byte from dots
def byte_encode(dots):
b = 0
dots = dots[1:]
for c in dots:
b |= (1 << (int(c) - 1))
return "\\x{:02x}".format(b)
if __name__ == "__main__":
main()